 Nicolas Malburet - 10 juil. 2025
Nicolas Malburet - 10 juil. 2025LLM : Les bases de l'IA générative expliquées
L'intelligence artificielle générative révolutionne notre façon de travailler, de créer et d'interagir avec l'information. Mais derrière les interfaces familières de ChatGPT ou Claude se cachent des mécanismes complexes que peu de personnes comprennent vraiment.
Comment fonctionne exactement un modèle de langage ? Pourquoi certains prompts génèrent-ils de meilleurs résultats que d'autres ? Quelles sont les différences fondamentales entre les modèles disponibles sur le marché ?
Cette plongée technique dans l'univers des LLM vous donnera les clés pour mieux comprendre et exploiter ces outils révolutionnaires. Que vous soyez développeur, product manager, testeur, ou simplement curieux de comprendre les rouages de l'IA, ce guide complet démystifie les concepts essentiels qui façonnent notre avenir numérique.
1. LLM : Comprendre les fondamentaux des modèles de langage
Les tokens : la langue secrète des LLM
Contrairement à ce que l'on pourrait penser, les modèles de langage ne comprennent ni les mots ni les lettres. Ils ne connaissent qu'une seule chose : les tokens.
Un token est simplement un nombre. Dans le modèle Llama 2, par exemple, il existe 300000 tokens différents, soit 300000 nombres distincts. Les LLM manipulent ces nombres en les plaçant les uns à la suite des autres.
C'est ensuite l'humain qui établit la correspondance : le nombre 42 pourrait correspondre au token "toto", le nombre 1337 au token "bonjour".
Le découpage du texte en tokens est optimisé pour représenter un maximum d'information avec un minimum de tokens. Chaque token peut être un mot complet avec un espace devant, permettant de découper une phrase longue en peu de tokens même si elle contient de nombreux caractères.
Il existe différentes façons de construire les tokens, voici comment GTP4 tokénise la phrase « Let’s learn about LLM with exFabrica! » :

Sous forme de nombres cela correspond aux tokens suivants : [10267, 753, 4048, 922, 445, 11237, 449, 506, 82831, 64, 0]
D’autres LLM peuvent bien sur aboutir à un découpage différent.
La seule chose qu’un LLM connait ce sont des nombres (tokens).
La génération probabiliste : pourquoi les LLM sont imprévisibles
Les LLM ne génèrent pas directement des tokens, mais une distribution des probabilités du prochain token.
Pour un prompt donné, le LLM indique la probabilité que chaque token potentiel soit le suivant.
Par exemple, si le LLM a déjà généré la phrase « Le meilleur langage de programmation est le », on a :
- 42% de chance pour le token "JavaScript"
- 23% de chance pour le token "C#"
- 18% de chance pour le token "Python"
C'est le processus d'inférence qui choisit ensuite le token à générer. Ce choix peut être le token avec la plus haute probabilité, ou pas.
La température est le paramètre qui modifie cette sélection. Une température élevée augmente les chances de choisir un token qui n'a pas la plus haute probabilité, rendant la génération plus créative mais moins prévisible.
Changer un seul mot dans votre prompt peut radicalement modifier la distribution des probabilités du prochain token. Cette extrême sensibilité explique pourquoi le prompt engineering est si crucial.
Les hallucinations : quand l'IA s'égare
Les hallucinations se produisent lorsque le LLM s'écarte complètement du sujet attendu.
Elles découlent de la nature probabiliste de la génération. Si le processus d'inférence choisit un token qui n'a que 5% de chance de sortir (à cause de la température), le LLM doit ensuite générer le token suivant en se basant sur ce token potentiellement erroné.
Une fois qu'un token erroné est dans la réponse, le LLM va continuer à générer des tokens qui sont probables étant donné ce nouveau contexte, même s'il est complètement à côté de la plaque.
Il est difficile de comprendre à quel endroit le LLM a commencé à diverger.
Les hallucinations sont un problème constant et on ne peut pas complètement les éviter pour l'instant.
Il existe des techniques pour les réduire :
- Inclure dans le prompt une instruction demandant au LLM de répondre "I don't know" s'il n'est pas sûr
- Pour les cas critiques (exemple : médical), nous pouvons configurer le système pour qu'il ne traite que les cas où il est extrêmement sûr
- Demander au LLM de générer plusieurs réponses et prendre la plus fréquente
- Faire valider le résultat par un second modèle, ou par des règles métier spécifiques
Il y a toujours besoin d'un humain dans la boucle pour pallier les limites des LLM et valider les résultats. Ce sont des "copilotes", pas des "pilotes autonomes".
Le processus d'inférence : une boucle infinie de génération
L'inférence, c'est un processus de boucle de génération de token. Un LLM, dans sa forme la plus basique, a une seule fonction : en fonction d'une fenêtre de contexte (votre prompt), il génère les probabilités du token suivant.
Voici comment cela fonctionne concrètement :

Cette boucle continue jusqu'à ce qu'un token spécial appelé stop token soit généré, indiquant que le LLM n'a plus rien à dire. À la réception de ce signal, le processus s'arrête et renvoie la réponse complète.
L'inférence est une boucle qui appelle le modèle de manière répétée pour générer chaque token séquentiellement.
La fenêtre contextuelle : mémoire immédiate du LLM
La fenêtre contextuelle est une notion centrale pour comprendre les capacités d’un grand modèle de langage (LLM). Elle désigne la quantité maximale d’informations que le modèle peut "voir" et prendre en compte en une seule fois, c’est-à-dire le nombre de tokens qu’il peut traiter simultanément.
Contrairement à une mémoire humaine de long terme, un LLM n’a pas de souvenir durable d’une conversation passée : il ne fonctionne qu’avec ce qui lui est donné dans cette fenêtre. Si l’information dépasse cette limite, le modèle l’oublie tout simplement.
Les tailles de fenêtres varient considérablement d’un modèle à l’autre.
- GPT-4o peut gérer jusqu’à 128 000 tokens, ce qui représente environ 300 pages de texte.
- Le modèle Claude 3 de chez Anthropic va encore plus loin, avec une capacité de 200 000 tokens
- À l’inverse, LLaMA 2, un modèle open-source de Meta, est limité à 4 096 tokens, soit à peine quelques pages de texte.
Cette disparité a un impact direct sur la profondeur des raisonnements qu’on peut demander à chaque modèle.
En résumé, plus la fenêtre est large, plus le LLM peut travailler de manière riche, contextuelle et pertinente — sans sacrifier de mémoire au fil du dialogue.
L'architecture technique d'un LLM
Un LLM se compose de plusieurs éléments distincts :

- Le code du modèle : un empilement de couches de réseaux de neurones qui définit l'architecture (voir illustration)
- Les poids : stockés dans un fichier volumineux, ils représentent la connaissance du modèle. Ces poids sont le résultat de l'entraînement sur un dataset massif.
- L'entraînement ajuste progressivement ces poids pour que le réseau prédise correctement le token suivant. La connaissance du modèle est stockée sous la forme de ces poids, pas sous forme de tokens.
C'est un peu comme des potentiels dans un réseau de neurones qui s'activent selon le contexte. Ces poids sont ensuite utilisés par le code du processus d'inférence pour générer du texte.
Les données d'entraînement : la base de la connaissance
Les données utilisées pour entraîner les LLM sont d'une variété impressionnante.
Cela inclut tout ce qui est public sur internet, et potentiellement des contenus sous droit d'auteur comme des livres ou des articles privés. Les LLM ont ainsi une vaste connaissance de données publiques : documentations techniques, tutoriels, forums...
Mais attention : les modèles ne savent pas quelle est la "meilleure" donnée. Pour eux, la "meilleure" est celle qui est apparue le plus de fois pendant l'entraînement.
Le poids d'une source dans l'entraînement est décidé par ceux qui créent les jeux de données. Entraîner un modèle 100 fois sur Wikipédia et 1 fois sur Le Monde donnera 100 fois plus d'influence aux données de Wikipédia sur les poids du modèle.
La qualité de la donnée d'entraînement est cruciale : si vous l'entraînez avec de mauvaises données, vous obtiendrez de mauvais résultats (on entend souvent l’expression “Garbage In, Garbage Out”).
Le fine-tuning : spécialiser un modèle existant
Il est possible de réentraîner les modèles, ou plus précisément, de réentraîner certaines couches ou certains poids avec de nouvelles données d'entraînement.
Le fine-tuning modifie certains poids du LLM. Par exemple, réentraîner un LLM avec des dossiers médicaux lui donnera une connaissance spécifique de ce domaine, améliorant ses performances pour cet usage.
Cependant, le fine-tuning coûte très cher : des milliers, des dizaines, voire des centaines de milliers d'euros en cartes graphiques et consommation électrique.
En général, le prompt engineering seul est suffisant. Le fine-tuning n'est utilisé que pour des cas très précis après avoir épuisé les possibilités du prompt engineering.
Un inconvénient majeur du fine-tuning est qu’on ne peut pas "désapprendre". Si une information change (comme un prix dans un catalogue), réentraîner le modèle avec la nouvelle information ne supprimera pas l'ancienne connaissance. Le modèle aura appris les deux, créant une probabilité qu'il donne l'ancienne information.
Les encastrements vectoriels : capturer le sens des mots
Les encastrements vectoriels (“vector embeddings”) sont une innovation pratique liée aux LLM.
Ils permettent de représenter le sens sémantique d'un texte sous forme de vecteur, un tableau de nombres. Les vecteurs d'OpenAI ont par exemple 1536 dimensions (1536 chiffres).
On peut effectuer des opérations mathématiques classiques sur ces vecteurs : addition, soustraction, calcul de distance.
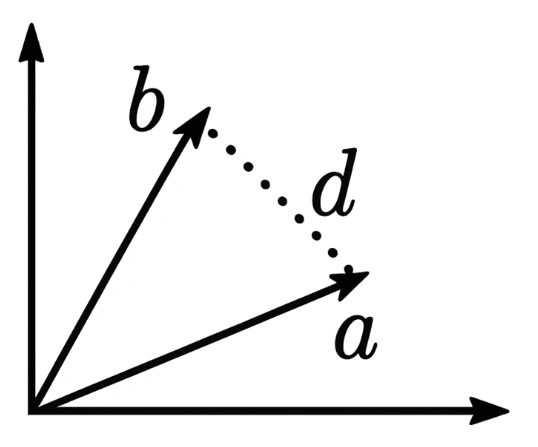
La distance entre deux vecteurs indique à quel point deux textes ont le même sens. Plus la distance est petite, plus le sens est proche. L’illustration montre une distance (d) entre deux vecteurs à 2 dimensions (a et b).
Les vecteurs permettent une recherche sémantique très performante, bien meilleure qu'auparavant. Ils sont utilisés pour retrouver des textes ayant un sens similaire à une question d'utilisateur.
✅ Checklist : Maîtriser les fondamentaux des LLM
- [ ] Comprendre que les LLM ne manipulent que des tokens (nombres)
- [ ] Intégrer la nature probabiliste de la génération dans vos attentes
- [ ] Implémenter des garde-fous contre les hallucinations
- [ ] Maintenir une supervision humaine des résultats critiques
- [ ] Assimiler le processus d'inférence comme une boucle de génération
- [ ] Identifier les composants techniques : code, poids, données d'entraînement
- [ ] Évaluer le besoin réel de fine-tuning vs prompt engineering
2. Modèles : Naviguer dans l'écosystème des LLM
Sécurité et confidentialité : une distinction cruciale
Il est crucial de ne pas confondre des applications comme ChatGPT avec les modèles sous-jacents comme GPT-4o (API).
ChatGPT (application grand public) peut utiliser vos données pour l'entraînement selon les options choisies. Il a des conditions d'utilisation et des SLA différents.
Les API d'entreprise comme GPT-4o (ou d'autres providers) ne sauvegardent pas vos données, ne les utilisent pas pour l'entraînement, et sont soumises à des politiques de confidentialité strictes et des SLA professionnels.
Envoyer des données à l'API de GPT-4o est comparable à envoyer des données à Amazon S3 en termes de confidentialité.
Malheureusement, les entreprises comprennent encore mal cette distinction importante pour la sécurité et la confidentialité.
Évaluer les modèles : au-delà du marketing
Il est actuellement difficile de déterminer quel modèle est objectivement le "meilleur".
Il existe des benchmarks académiques et des leaderboards comme livech.ai qui évaluent les modèles sur leur capacité à résoudre des tâches spécifiques. Livebench.ai est un site de référence pour comparer les performances objectives.
En pratique, les modèles majeurs actuels (GPT, Claude, Gemini) sont souvent assez proches en termes de performance, avec des différences plus notables sur la rapidité de génération.
Le choix peut dépendre de l'infrastructure existante :
- Choisir Gemini si vous êtes sur Google Cloud
- Opter pour GPT si vous êtes sur Azure
- Préférer Claude pour certaines tâches de raisonnement complexe
Coûts d’utilisation des LLM
Les coûts liés à l’utilisation des modèles de langage (LLM) reposent essentiellement sur le nombre de tokens traités à chaque requête, aussi bien en entrée (prompt + contexte) qu’en sortie (réponse générée).
Plus le prompt est long, plus le coût augmente, et il en va de même pour la longueur de la réponse. Ces coûts sont généralement exprimés en dollars par millier de tokens (par ex. 0,01€/1k tokens pour l’entrée et 0,03€/1k tokens pour la sortie sur certains modèles).
Pour optimiser ces coûts, plusieurs leviers sont à considérer :
- D'abord, réduire la taille des prompts en évitant les redondances, en résumant les instructions, ou en sélectionnant les informations les plus pertinentes.
- Ensuite, limiter la longueur maximale de la sortie ou contrôler le style de réponse permet de réduire la consommation en sortie.
- Un autre paramètre important est la température : en la réduisant (vers 0), on limite la variabilité et donc souvent la longueur des réponses. Cela peut aussi améliorer la cohérence, bien que cela dépende du cas d’usage.
- Enfin, le choix du modèle joue un rôle clé. Un modèle plus petit comme GPT-3.5 ou Mistral peut suffire pour des tâches simples ou structurées, réduisant considérablement les coûts.
- De plus, l’utilisation de mécanismes de mise en cache (caching des réponses fréquentes ou des appels à chaînes d'agents) permet d’éviter des requêtes redondantes et donc de réduire la facture globale. Dans des systèmes en production, cette stratégie peut engendrer des économies substantielles sans perte de qualité perceptible.
LLM vs SLM : taille et performance
On distingue les Large Language Models (LLM) et les Small Language Models (SLM).
La principale différence réside dans la taille, mesurée par le nombre de paramètres (coefficients ou poids). Ce chiffre est souvent exprimé en milliards (B).
Exemples de tailles :
- GPT-4 : ~1,700 milliards de paramètres
- Llama 2 70B : 70 milliards de paramètres
- Llama 2 7B : 7 milliards de paramètres
Les SLM sont plus petits, donc :
- Plus rapides à exécuter
- Moins chers à utiliser
- Mais généralement moins performants sur les tâches complexes
Il existe aussi des modèles de "raisonnement" qui effectuent un traitement interne avant de produire leur réponse, comme les modèles de la série "o" d'OpenAI.
Modèles ouverts vs fermés
- Modèles fermés, accessibles uniquement via API :
- Modèles ouverts :
Les modèles ouverts permettent :
- Un contrôle total sur l'hébergement
- Une personnalisation complète
- Aucune dépendance externe
- Mais nécessitent une infrastructure dédiée
Modèles spécialisés : la niche technique
Il existe des modèles qui ont été fine-tunés pour des tâches ou des domaines spécifiques :
- Génération de code : Code Llama, GitHub Copilot
- Domaine médical : Med-PaLM, BioBERT
- Domaine légal : LegalBERT
- Finance : BloombergGPT
Cependant, l'utilisation de ces modèles très spécialisés reste encore assez anecdotique comparée aux modèles généralistes, qui excellent souvent dans la plupart des domaines avec un bon prompt engineering.
✅ Checklist : Choisir le bon modèle
- [ ] Identifier vos besoins de confidentialité (API vs application grand public)
- [ ] Évaluer les performances sur des benchmarks objectifs
- [ ] Considérer votre infrastructure existante (cloud provider)
- [ ] Calculer le coût total (tokens, latence, volume)
- [ ] Tester plusieurs modèles sur vos cas d'usage réels
- [ ] Vérifier la disponibilité et les SLA des fournisseurs
- [ ] Évaluer le besoin réel de modèles spécialisés vs généralistes
Conclusion : Maîtriser l'IA générative pour transformer votre activité
Les modèles de langage tels que les LLM fascinent autant qu’ils déconcertent. Derrière leur apparente intelligence se cache un mécanisme rigoureux, fondé sur des mathématiques, des probabilités et des quantités massives de données. Comprendre leur fonctionnement — de la tokenisation à l’inférence, en passant par les vecteurs et le fine-tuning — permet de mieux cerner leurs forces, leurs limites et leurs dérives.
Ce savoir n’est pas réservé aux ingénieurs : il est crucial pour quiconque utilise, conçoit ou critique des outils fondés sur l’IA. Car pour exploiter pleinement la puissance des LLM, il ne suffit pas de leur poser des questions — il faut savoir leur parler.
Justement, comment parle-t-on à une IA ?
C’est l’objet du prochain article, où nous plongerons dans l’univers du prompt engineering : l’art de structurer ses instructions pour obtenir des réponses pertinentes, fiables, et parfois surprenantes. Un guide indispensable pour passer du simple utilisateur au véritable architecte d’interactions intelligentes.