 Nicolas Malburet - Jul 10, 2025
Nicolas Malburet - Jul 10, 2025LLM : The Basics of Generative AI Explained
Generative artificial intelligence is revolutionizing the way we work, create, and interact with information. But behind the familiar interfaces of ChatGPT or Claude lie complex mechanisms that few people truly understand.
How exactly does a language model work? Why do some prompts generate better results than others? What are the fundamental differences between the models available on the market?
This technical dive into the world of LLMs will give you the keys to better understand and leverage these revolutionary tools. Whether you are a developer, product manager, tester, or simply curious to understand the workings of AI, this comprehensive guide demystifies the essential concepts shaping our digital future.
1. LLM: Understanding the fundamentals of language models
Tokens: the secret language of LLMs
Contrary to what one might think, language models do not understand words or letters. They know only one thing: tokens.
A token is simply a number. In the Llama 2 model, for example, there are 300,000 different tokens, or 300,000 distinct numbers. LLMs manipulate these numbers by placing them one after another.
It is then the human who establishes the correspondence: the number 42 could correspond to the token "toto", the number 1337 to the token "bonjour".
The splitting of text into tokens is optimized to represent as much information as possible with a minimum of tokens. Each token can be a complete word with a space in front, allowing a long sentence to be split into few tokens even if it contains many characters.
There are different ways to construct tokens, here is how GTP4 tokenizes the sentence "Let’s learn about LLM with exFabrica!":

In the form of numbers, this corresponds to the following tokens: [10267, 753, 4048, 922, 445, 11237, 449, 506, 82831, 64, 0]
Other LLMs can of course result in a different split.
The only thing an LLM knows is numbers (tokens).
Probabilistic generation: why LLMs are unpredictable
LLMs do not directly generate tokens, but a probability distribution of the next token.
For a given prompt, the LLM indicates the probability that each potential token will be next.
For example, if the LLM has already generated the sentence "The best programming language is", we have:
- 42% chance for the token "JavaScript"
- 23% chance for the token "C#"
- 18% chance for the token "Python"
It is the inference process that then chooses the token to generate. This choice can be the token with the highest probability, or not.
Temperature is the parameter that modifies this selection. A high temperature increases the chances of choosing a token that does not have the highest probability, making the generation more creative but less predictable.
Changing a single word in your prompt can radically change the probability distribution of the next token. This extreme sensitivity explains why prompt engineering is so crucial.
Hallucinations: when AI goes astray
Hallucinations occur when the LLM completely deviates from the expected subject.
They result from the probabilistic nature of generation. If the inference process chooses a token that has only a 5% chance of coming out (because of the temperature), the LLM must then generate the next token based on this potentially erroneous token.
Once an erroneous token is in the response, the LLM will continue to generate tokens that are probable given this new context, even if it is completely off track.
It is difficult to understand where the LLM started to diverge.
Hallucinations are a constant problem and cannot be completely avoided for now.
There are techniques to reduce them:
- Include in the prompt an instruction asking the LLM to answer "I don't know" if it is not sure
- For critical cases (e.g. medical), we can configure the system to only handle cases where it is extremely confident
- Ask the LLM to generate several answers and take the most frequent one
- Have the result validated by a second model, or by specific business rules
There is always a need for a human in the loop to compensate for the limitations of LLMs and validate the results. They are "copilots", not "autonomous pilots".
The inference process: an infinite generation loop
Inference is a process of looping token generation. An LLM, in its most basic form, has a single function: based on a context window (your prompt), it generates the probabilities of the next token.
Here is how it works concretely:
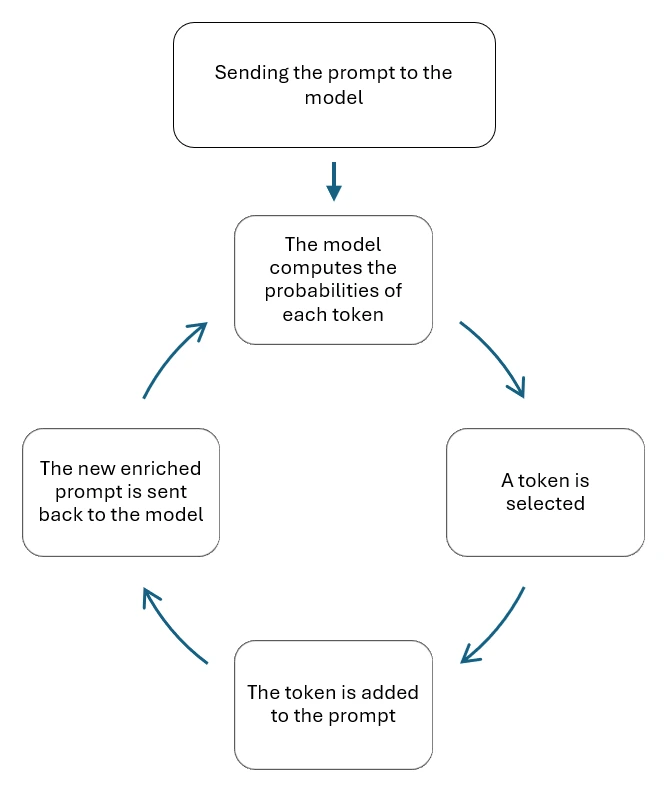
This loop continues until a special token called a stop token is generated, indicating that the LLM has nothing more to say. Upon receiving this signal, the process stops and returns the complete response.
Inference is a loop that repeatedly calls the model to generate each token sequentially.
The context window: LLM's immediate memory
The context window is a central concept for understanding the capabilities of a large language model (LLM). It refers to the maximum amount of information the model can "see" and take into account at one time, i.e., the number of tokens it can process simultaneously.
Unlike human long-term memory, an LLM has no lasting memory of a past conversation: it only works with what is given to it in this window. If the information exceeds this limit, the model simply forgets it.
Window sizes vary considerably from one model to another.
- GPT-4o can handle up to 128,000 tokens, which is about 300 pages of text.
- The Claude 3 model from Anthropic goes even further, with a capacity of 200,000 tokens
- Conversely, LLaMA 2, an open-source model from Meta, is limited to 4,096 tokens, just a few pages of text.
This disparity has a direct impact on the depth of reasoning you can ask each model.
In summary, the wider the window, the more richly, contextually, and relevantly the LLM can work—without sacrificing memory over the course of the dialogue.
The technical architecture of an LLM
An LLM consists of several distinct elements:
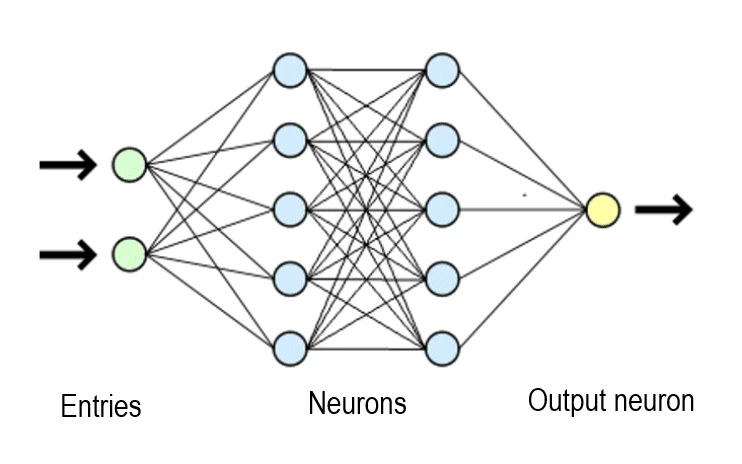
- The model code: a stack of neural network layers that defines the architecture (see illustration)
- The weights: stored in a large file, they represent the model's knowledge. These weights are the result of training on a massive dataset.
- Training gradually adjusts these weights so that the network correctly predicts the next token. The model's knowledge is stored in these weights, not as tokens.
It's a bit like potentials in a neural network that activate according to the context. These weights are then used by the inference process code to generate text.
Training data: the foundation of knowledge
The data used to train LLMs is impressively varied.
This includes everything that is public on the internet, and potentially copyrighted content such as books or private articles. LLMs thus have vast knowledge of public data: technical documentation, tutorials, forums...
But beware: models do not know what the "best" data is. For them, the "best" is what appeared most often during training.
The weight of a source in training is decided by those who create the datasets. Training a model 100 times on Wikipedia and once on Le Monde will give Wikipedia data 100 times more influence on the model's weights.
The quality of training data is crucial: if you train it with bad data, you will get bad results (the expression "Garbage In, Garbage Out" is often heard).
Fine-tuning: specializing an existing model
It is possible to retrain models, or more precisely, to retrain certain layers or weights with new training data.
Fine-tuning modifies certain weights of the LLM. For example, retraining an LLM with medical records will give it specific knowledge of this field, improving its performance for this use.
However, fine-tuning is very expensive: thousands, tens, or even hundreds of thousands of euros in graphics cards and electricity consumption.
In general, prompt engineering alone is sufficient. Fine-tuning is used only for very specific cases after exhausting the possibilities of prompt engineering.
A major drawback of fine-tuning is that you cannot "unlearn". If information changes (such as a price in a catalog), retraining the model with the new information will not remove the old knowledge. The model will have learned both, creating a probability that it will give the old information.
Vector embeddings: capturing the meaning of words
Vector embeddings are a practical innovation related to LLMs.
They allow the semantic meaning of a text to be represented as a vector, an array of numbers. OpenAI vectors, for example, have 1536 dimensions (1536 numbers).
You can perform standard mathematical operations on these vectors: addition, subtraction, distance calculation.
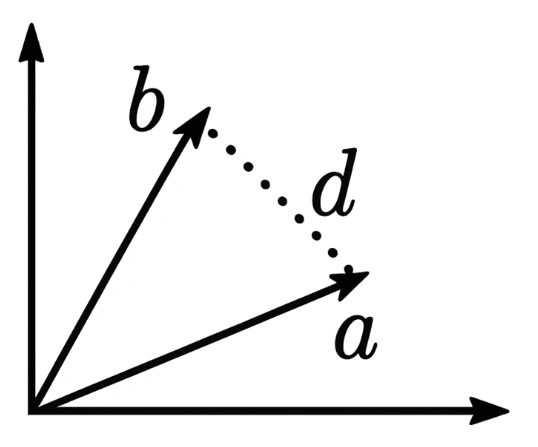
The distance between two vectors indicates how similar two texts are in meaning. The smaller the distance, the closer the meaning. The illustration shows a distance (d) between two 2-dimensional vectors (a and b).
Vectors enable very efficient semantic search, much better than before. They are used to find texts with a meaning similar to a user's question.
✅ Checklist: Mastering the fundamentals of LLMs
- [ ] Understand that LLMs only manipulate tokens (numbers)
- [ ] Integrate the probabilistic nature of generation into your expectations
- [ ] Implement safeguards against hallucinations
- [ ] Maintain human supervision of critical results
- [ ] Assimilate the inference process as a generation loop
- [ ] Identify technical components: code, weights, training data
- [ ] Assess the real need for fine-tuning vs prompt engineering
2. Models: Navigating the LLM ecosystem
Security and privacy: a crucial distinction
It is crucial not to confuse applications like ChatGPT with the underlying models like GPT-4o (API).
ChatGPT (consumer application) may use your data for training depending on the options chosen. It has different terms of use and SLAs.
Enterprise APIs like GPT-4o (or other providers) do not save your data, do not use it for training, and are subject to strict privacy policies and professional SLAs.
Sending data to the GPT-4o API is comparable to sending data to Amazon S3 in terms of privacy.
Unfortunately, companies still misunderstand this important distinction for security and privacy.
Evaluating models: beyond marketing
It is currently difficult to determine which model is objectively the "best".
There are academic benchmarks and leaderboards like livech.ai that evaluate models on their ability to solve specific tasks. Livebench.ai is a reference site for comparing objective performance.
In practice, the major current models (GPT, Claude, Gemini) are often quite close in terms of performance, with more notable differences in generation speed.
The choice may depend on existing infrastructure:
- Choose Gemini if you are on Google Cloud
- Opt for GPT if you are on Azure
- Prefer Claude for certain complex reasoning tasks
LLM usage costs
The costs associated with using language models (LLMs) are essentially based on the number of tokens processed per request, both for input (prompt + context) and output (generated response).
The longer the prompt, the higher the cost, and the same goes for the length of the response. These costs are generally expressed in dollars per thousand tokens (e.g., €0.01/1k tokens for input and €0.03/1k tokens for output on some models).
To optimize these costs, several levers should be considered:
- First, reduce the size of prompts by avoiding redundancies, summarizing instructions, or selecting the most relevant information.
- Then, limit the maximum length of the output or control the response style to reduce output consumption.
- Another important parameter is temperature: by reducing it (towards 0), you limit variability and often the length of responses. This can also improve consistency, although it depends on the use case.
- Finally, the choice of model plays a key role. A smaller model like GPT-3.5 or Mistral may suffice for simple or structured tasks, significantly reducing costs.
- Additionally, using caching mechanisms (caching frequent responses or agent chain calls) avoids redundant requests and thus reduces the overall bill. In production systems, this strategy can generate substantial savings without perceptible loss of quality.
LLM vs SLM: size and performance
We distinguish between Large Language Models (LLM) and Small Language Models (SLM).
The main difference lies in size, measured by the number of parameters (coefficients or weights). This figure is often expressed in billions (B).
Size examples:
- GPT-4: ~1,700 billion parameters
- Llama 2 70B: 70 billion parameters
- Llama 2 7B: 7 billion parameters
SLMs are smaller, so:
- Faster to run
- Cheaper to use
- But generally less performant on complex tasks
There are also "reasoning" models that perform internal processing before producing their response, such as OpenAI's "o" series models.
Open vs closed models
- Closed models, accessible only via API:
- Open models:
Open models allow:
- Full control over hosting
- Complete customization
- No external dependency
- But require dedicated infrastructure
Specialized models: the technical niche
There are models that have been fine-tuned for specific tasks or domains:
- Code generation: Code Llama, GitHub Copilot
- Medical domain: Med-PaLM, BioBERT
- Legal domain: LegalBERT
- Finance: BloombergGPT
However, the use of these highly specialized models is still quite anecdotal compared to generalist models, which often excel in most domains with good prompt engineering.
✅ Checklist: Choosing the right model
- [ ] Identify your privacy needs (API vs consumer application)
- [ ] Evaluate performance on objective benchmarks
- [ ] Consider your existing infrastructure (cloud provider)
- [ ] Calculate total cost (tokens, latency, volume)
- [ ] Test several models on your real use cases
- [ ] Check provider availability and SLAs
- [ ] Assess the real need for specialized vs generalist models
Conclusion: Mastering generative AI to transform your business
Language models such as LLMs are as fascinating as they are puzzling. Behind their apparent intelligence lies a rigorous mechanism, based on mathematics, probabilities, and massive amounts of data. Understanding how they work—from tokenization to inference, through vectors and fine-tuning—allows you to better grasp their strengths, limitations, and pitfalls.
This knowledge is not reserved for engineers: it is crucial for anyone who uses, designs, or critiques AI-based tools. Because to fully exploit the power of LLMs, it is not enough to ask them questions—you have to know how to talk to them.
Precisely, how do you talk to an AI?
That is the subject of the next article, where we will dive into the world of prompt engineering: the art of structuring your instructions to get relevant, reliable, and sometimes surprising answers. An essential guide to move from simple user to true architect of intelligent interactions.