 Nicolas Malburet - Jul 11, 2025
Nicolas Malburet - Jul 11, 2025LLM & Prompt Engineering : The complete guide to using them effectively
Language models are powerful, but their effectiveness depends above all on the quality of the instructions we give them. This article guides you step by step through the art of prompt engineering : how to structure a request, avoid pitfalls, and harness the full potential of LLMs.
Throughout the sections, you will also learn to identify truly useful technical use cases, and to understand how autonomous agents work—these enhanced LLMs capable of acting and reasoning on their own.
An essential guide to move from a simple user to a true architect of intelligent interactions.
1. Prompt Engineering 101: The Art of Communicating with AI
The crucial importance of prompt engineering
Prompt engineering, or the art of writing good instructions for the LLM, is extremely important. About 80% of performance improvement work can be done at this level.
A good prompt can significantly improve generation quality, sometimes dramatically.
Why is it so effective? Because you directly influence the probability distribution of the next token. Every word in your prompt matters.
The ideal structure of a prompt
A good prompt structure should ideally contain three elements:
- Clear, well-written, and structured instructions
Be precise in your requests. Instead of "Write something about cars," prefer "Write a 150-word paragraph explaining the benefits of electric cars for urban environments."
It is important to write a prompt as precisely as possible; a vague prompt ("Tell me about cars") will yield mediocre results. Also avoid ambiguity and double negatives.
- Delimited and identified external data
For data you include in the prompt that are not instructions (code, document, etc.), use delimiters.
Examples of effective delimiters:
- Backticks for code:
function foobar() { return 42 ; }- Markdown, to identify different parts of the prompt:
# Code code here # Output format …- XML tags for documents:
<start_document> content <end_document>This helps the LLM understand that this is external content and not instructions to follow. Models have been trained to differentiate instructions from such delimited external content.
- Instructions on the desired output format
Clearly specify the expected format: JSON, XML, table, list, structured outline...
This precision guides the generation toward the desired result.
Highlighting critical instructions
Since LLMs have been trained on human data where capitalization highlights text, using uppercase for very important instructions significantly increases their impact on generation.
Example:
- IMPORTANT: Never generate medical content without a warning.
- MANDATORY:Strictly follow the requested JSON format.
This technique can correct recurring errors or enforce a specific format.
Few-shot prompting: learning by example
Few-shot prompting is a simple but highly effective technique: give one or more examples of the expected response to the LLM.
Including an example in the prompt increases the lexical field of the expected response and thus the probability that the LLM generates the tokens corresponding to the desired answer.
Practical example:
Extract the key information from this CV:
Example:
CV: "Jean Dupont, 5 years of experience in digital marketing at Google"
Output: {"name": "Jean Dupont", "experience": "5 years", "field": "digital marketing", "company": "Google"}
Now, process this CV:
[Your CV to analyze]
This technique greatly improves LLM performance.
Chain of Thought
This is a more complex but very effective technique to improve prompt capabilities.
It uses the inference mechanism: the tokens generated by the LLM are then used by the LLM itself to generate the following tokens.
The idea is to ask the LLM to generate intermediate steps or a plan before producing the final answer.
These tokens representing the "reasoning" are added to the prompt and guide subsequent generation toward a higher-quality result.
Even a simple instruction like "think step by step" can force the LLM to structure its thinking before generating the complete answer.
Concrete example:
Solve this problem step by step:
A company has 100 employees. 30% work in marketing, 40% in development, the rest in support. How many employees work in support?
The chain of thought uses the tokens generated by the LLM to improve the quality of its final output.
✅ Checklist: Mastering prompt engineering
- [ ] Structure your prompts in 3 parts: instructions, data, format
- [ ] Use clear delimiters for external data
- [ ] Use uppercase for critical instructions
- [ ] Include concrete examples (few-shot) when relevant
- [ ] Ask the LLM to think step by step for complex tasks
- [ ] Test and iterate on your prompts to optimize results
- [ ] Document your most effective prompts for reuse
2. Technical Use Cases: Harnessing the Power of LLMs
Exploration and information retrieval
The first major use case for LLMs is information retrieval.
Users now make requests to LLM-based applications (like ChatGPT) instead of traditional Google searches.
This approach allows for more precise and above all contextualized answers specific to the user's situation.
The impact is notable: developers use Stack Overflow less since the advent of ChatGPT, preferring to ask their technical questions directly to the AI.
Advantages of this approach:
- Personalized answers to the context
- No need to browse multiple sources
- Explanations adapted to the user's level
- Possibility to ask follow-up questions
Generation of structured entities
This is a very widespread and particularly powerful use case.
It involves using an LLM to take unstructured data (free text, documents) or user inputs and ask it to generate data in an expected structured format (often JSON).
This structured data can then be parsed and saved in a database.
Concrete examples:
- Product feature extraction:
Input: "iPhone 15 Pro Max, 256GB, blue titanium, 6.7-inch screen"
Output:{ "brand": "Apple", "model": "iPhone 15 Pro Max", "storage": "256GB", "color": "blue titanium", "screen_size": "6.7 inches" } - CV analysis:
Input: CV in free text
Output:{ "name": "Jean Dupont", "experience": "5 years", "skills": ["Python", "SQL", "Machine Learning"], "education": "Master in Computer Science" }
In the case of Didask, using LLMs to generate training plans tripled the team's productivity.
This use case allows automating the creation or extraction of business entities. It is also useful to help users fill out forms or generate initial content (blank page syndrome).
RAG: Retrieval Augmented Generation
RAG is a revolutionary method to allow LLMs to access knowledge not in their training data.
Typical use cases:
- Private company data
- Internal documentation
- Specific knowledge bases
- Frequently changing data
How does RAG work?- Ingestion: Data is grouped as text documents
- Indexing: This data is stored in a search engine with semantic capabilities as chunks (subparts of the document)
- Query: The user asks a question
- Search: The system finds the most relevant excerpts among those stored in the semantic search engine
- Augmentation: These excerpts are injected into the LLM's prompt
- Generation: The LLM responds using this external information
Technical architecture:
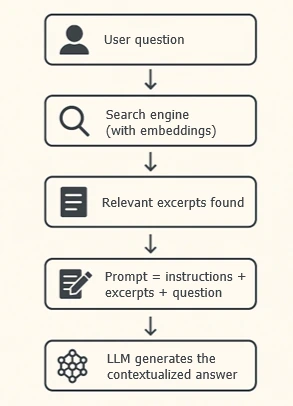
RAG allows the LLM to provide contextualized answers with specific information: customer databases, source code, technical documentation...
This approach is generally preferred over fine-tuning for frequently changing or very large data, as it is less expensive and does not suffer from the problem of impossible forgetting.
Concrete use cases:
- Internal support assistants
- Personalized sales assistance
- Onboarding help for new employees
- Technical assistance on proprietary code
Challenges associated with RAG
The composition of the search engine data strongly impacts RAG effectiveness.
It is essential that indexed documents are relevant, up-to-date, and structured in an exploitable way. Poor selection can lead to off-topic or inaccurate answers.
Chunking, i.e., splitting documents into segments (or chunks), is just as crucial: if too long, they may exceed the context window or dilute key information; too short, they lose the necessary context for understanding. Finding the right balance is essential to ensure precise retrievals and coherent answers.
✅ Checklist: Implementing technical use cases
For information retrieval:
- [ ] Identify your organization's critical information sources
- [ ] Assess the frequency of data updates
- [ ] Test search performance vs. existing solutions
For structured entity generation:
- [ ] Map your current data entry processes
- [ ] Define the desired JSON output schemas
- [ ] Create few-shot examples for each entity type
- [ ] Set up validation for generated structured data
- [ ] Measure productivity gains achieved
For RAG:
- [ ] Audit your internal data sources
- [ ] Choose your search engine (Elasticsearch, Pinecone, etc.)
- [ ] Implement the document ingestion pipeline
- [ ] Configure embedding generation
- [ ] Optimize search result relevance
- [ ] Test answer quality on real cases
3. What is an agent? Towards LLM autonomy
Definition and core concept
The term "agent" is a bit of a buzzword, but it refers to a specific and advanced use of LLMs.
An agent is the combination of a LLM and tools.
While classic LLMs simply generate text, agents can act in the real world thanks to the tools provided to them.
The mechanism of tools
LLMs generate text, and in the case of an agent, this text can be structured (for example, in JSON) to indicate an action to be executed via a tool.
A tool is generally:
- A programmatic function
- An API call
- An interaction with a database
- Sending an email
- Searching logs
- Code analysis
Example of action generation:
{
"action": "send_email",
"parameters": {
"to": "client@example.com",
"subject": "Order follow-up",
"body": "Your order is ready..."
}
}
The agent loop: action, result, reflection
The program external to the agent will parse the LLM's output (the action JSON) and execute the corresponding tool.
The tool's return (result, success, error) is then reinjected into the prompt sent to the LLM.
This ability to receive the result of its actions in the prompt allows the LLM to understand what happened and plan the next actions.
The complete loop:

State management: agent memory
An agent maintains a "state" consisting of all actions performed and their returns. This state is reinjected into the prompt at each step so the agent understands where it is in task execution.
This semi-autonomy allows the agent to perform complex tasks in several steps without constant human intervention.
Concrete examples of agents
- E-commerce assistant:
- Listens to customer conversations
- Detects buying signals
- Recommends products at the right time
- Manages the order process
- Debugging agent:
- Analyzes error logs
- Examines the corresponding source code
- Identifies probable causes of the bug
- Proposes solutions or fixes
- Technical support agent:
- Receives a customer ticket
- Searches the knowledge base
- Tests potential solutions
- Escalates if necessary
Technical challenges of agents
Agents are one of the most difficult concepts in LLM engineering.
Planning complexity:
- Managing multi-step tasks
- Recovering from execution errors
- Optimizing the order of actions
Web agents: Agents interacting with the web are particularly complex because of:
- The complexity of modern HTML
- User interface manipulations
- Increasing anti-bot measures on the internet
- The variability of websites
Reliability:
- Agents can fail at different stages
- Error handling must be robust
- Human supervision remains necessary for critical tasks
The future of agents
Agents represent the natural evolution of LLMs toward greater autonomy and practical utility.
They transform LLMs from simple text generators into true digital assistants capable of accomplishing complex tasks.
However, we are still in the early stages of this technology, and human supervision remains essential for production deployments.
✅ Checklist: Developing effective agents
Design:
- [ ] Clearly define the tasks the agent must accomplish
- [ ] Identify all tools needed for these tasks
- [ ] Design the state management architecture
- [ ] Plan for error and recovery cases
Development:
- [ ] Implement tools with robust error handling
- [ ] Create the agent loop (LLM → action → result → LLM)
- [ ] Thoroughly test each tool individually
- [ ] Validate interactions between multiple tools
Deployment:
- [ ] Set up monitoring of agent actions
- [ ] Configure alerts for critical failures
- [ ] Plan escalation to human supervision
- [ ] Document the limits and supported use cases
Conclusion: Mastering Generative AI to Transform Your Business
Generative artificial intelligence is no longer an emerging technology reserved for tech giants. It has become a strategic, accessible tool that is already transforming how we work, create, and innovate.
Understanding the underlying mechanisms of LLMs gives you a decisive competitive advantage. You now know that behind every answer lies a complex probabilistic process, that each generated token influences the next, and that the quality of your prompts directly determines the relevance of the results obtained.
Prompt engineering is your most immediate and profitable lever. Before investing in costly fine-tuning or complex infrastructures, fully exploit the techniques we have covered: clear structuring, appropriate delimiters, concrete examples, chain of thought.
The technical use cases we have explored—from simple information retrieval to autonomous agents—illustrate the range of possibilities. But remember: start simple, measure results, then gradually increase complexity.
The model ecosystem is evolving rapidly, but the fundamental principles remain constant. Whether you choose GPT, Claude, Gemini, or Llama, the same rules apply: the quality of training data determines capabilities, human supervision remains essential, and hallucinations are part of the landscape.
Agents represent the near future of this technology, transforming LLMs into true digital assistants. But this increased autonomy comes with technical complexity and reliability challenges that must be anticipated.
Your next step? Identify a concrete use case in your organization, start with a simple prototype, and iterate based on the fundamentals you now master.
Generative AI is not magic—it's applied engineering with method. And you now have the keys to use it effectively.
Ready to take action ? Start by auditing your current processes, identify repetitive tasks that could benefit from intelligent automation, and launch your first pilot project. The future belongs to those who master these tools today.